
하지만 이런 게 정말 좋기만 한 걸까? 지식이란 스스로 노력하고시간을 들여 얻어야 오래 가는 법이다. 우리는 막강한 검색 엔진덕분에 너무나 쉽게 정보를 얻는다. 가끔‘머잖아 우리는 인터넷없이는 아무 것도 알지 못하는 바보가 되는 것이 아닐까’하는 생각이 들기도 한다. 조금 불편하더라도 들여다보고 찾아보면서 조금씩 조금씩 올바른 정보를 얻게 해주는 진정한‘검색 영웅’이 나왔으면좋겠다.
| 인터넷이 그저 새롭고 신기한 21세기의 부록 같았던 10여년 전, 그때만 해도 우리는 브라우저를 띄우고 그다지 망설일 필요가 없었다. 거의 모든 정보가 최초의 포털인 야후 한 곳에 잘 정리되어 있었기 때문이다. 당시 야후의 검색 서비스는 검색 로봇이 결과를 알려주는 것이 아니라 사람들이일일이 정보를 입력하고 분류하는 디렉토리 방식이었다. 지금 생각하면코미디영화에서나나올법한풍경이다. 지금은 어떤가? 시간이 흐를수록 웹 사이트와 웹 페이지 수는 헤아릴 수 없을 만큼 폭발적으로 늘어난다. 넷크래프트와 야후의 발표에 따르면 2005년 기준으로 7천만 개의 웹 사이트와 192억 개의웹 페이지가 검색되었다고 한다. 2007년 현재는 약 297억 개 정도의 웹 페이지가 있을 것으로 추정된다. 이 정도로 숫자가 많아지면수작업으로 했던 예전 방식으로는 도저히 원하는 페이지를 찾을수가 없다. 1페이지를 훑어보는 데 약 5초가 걸린다고 한다면 297억 개의 웹 페이지를 전부 볼 때는 페이지를 열고 닫는 시간을 빼고도 172일이나 걸린다. 검색 엔진의 힘이 절대적으로 필요한 시대가된것이다. 그렇다면 지금 우리가 이용하고 있는 검색 엔진은 얼마만큼의 능력을 가지고 있을까? 우리가 원하는 정보를 얼마나 빠르게, 얼마나제대로 찾아주고 있을까? 사람들의 갖가지 취향을 얼마나 만족시켜주고있는것일까? 검색 엔진이 돌아가는 기본 원리는 서비스마다 거의 비슷하다. 전세계의 웹 페이지를 수집해 DB화 시킨 후 어떤 페이지가 중요한것인지를 판단해서 이용자에게 적합한 결과를 보여주는 식이다. 검색 서비스마다 기술적인 노하우와 방법이 각기 다르고 외부에잘 알려져 있지 않아 그 안을 들여다 볼 수는 없지만 검색 결과를잘살피면그차이가어느정도인지알아볼수있다. 열린 검색, 닫힌 검색?! 각 사이트의 검색 로봇이 특정 페이지의 정보를 가져가지 못하도록 막는 데는 여러 가지 이유가 있을 것이다. 쉴 새 없이 자동으로웹 페이지들을 긁어가는 이 로봇의 활동을 막는 방법은 예상외로굉장히간단하다. 서버의 루트 디렉토리에‘robots.txt’라는 파일을 만들고 그 안에다음과같은식으로적는다.
모든 디렉토리에서 모든 검색 로봇의 접근을 허용하지 않으려면다음과같이한다.
만약 데이터 디랙토리에 구글봇의 접근을 막고 싶다면 다음과 같이하면된다
|
|

| 최근 일어난 검색에 대한 몇몇 사건을 떠올려 보자. 네이버는 카우봇으로 다른 웹 페이지들을 크롤링해 정리하고 이를 검색에 활용한다. 하지만 네이버 안에서 서비스되고 있는 정보들이 다른 검색엔진으로부터 크롤링되는 것은 막고 있다. 이것을 네이버가 포털의 기능과 함께 검색 엔진을 동시에 가지고 있기 때문이라고 이해해야 할지, 아니면 다른 서비스의 컨텐츠는 자사 서비스 안에서 보여주고 자사 서비스는 아무에게도 공개하지 않으려는 놀부 심보로봐야할지잘모르겠다. SK커뮤니케이션즈의 정책 또한 네이버와 비슷하다. 엠파스를 인수했음에도 불구하고 그동안 방대한 싸이월드의 컨텐츠는 싸이월드와 네이트 안에서만 검색되었다. 지난 3월 중순에는 네이트의검색 엔진이 엠파스로 바뀌면서 세 사이트가 같은 검색 결과를 나타내게 되었다. 검색할 때 표시되는 광고체계를 단일화하고 이를바탕으로광고수익을 올리려는뜻이아닌가싶다. 엠파스는 네이버의 아성에 도전할 당시부터‘열린 검색’이라는 이름 아래 종전에 검색이 잘 되지 않던 것들, 이른바 검색의 범위를다른 포털들까지 포함시켰다. 이 문제가 이슈화된 것은 네이버가robots.txt에 다른 검색 로봇의 접근을 막았는데도 그걸 무시하고정보를 얻었기 때문이다. 재미있는 것은 이런 엠파스가 정보 공개에 폐쇄적인 정책을 펴는 SK커뮤니케이션즈의 울타리로 들어갔다는 점이다. 엠파스의 검색 엔진을 단 네이트와 싸이월드가 네이버처럼폐쇄적인서비스를할지, 열린검색을할지주목된다. 예전 검색 엔진들의 검색 결과 출력 순서는 그 검색 엔진이 판단한 해당 문서의 정확도와 중요도를 따랐다. 하지만 요즘 검색 엔진은 이것들 외에도 여러 가지 카테고리를 구분해 보여준다. 대부분의 검색 엔진이 다른 서비스와 함께 운영되거나 포털의 일부로서비스되고 있기 때문에 각 회사의 정책에 따라 조금씩 다르게 나타난다. 한글 서비스를 하는 검색 엔진들 중에서 구글을 제외한 거의 모든검색 서비스가 비슷한 형태로 검색 결과를 보여준다. 검색어를 넣으면 관련 검색어를 보여주고 특정 키워드에 반응하는 상세 정보가 있으면 그걸 제일 우선으로 보여주는 식이다. 거기에 뉴스, 웹페이지, 블로그, 카페, 게시판, 동영상, 각종 지식문답 서비스의 컨텐츠를 보여주는데, 서비스마다 중요시하고 있는 것들을 위쪽에배치한다. 오른쪽 윗부분에는 주로 각종 실시간 검색어 순위를 보여준다. |
| 네이버 검색창에‘여행’이라는 키워드를 입력하면 스폰서링크(광고), 파워링크(광고), 플러스프로(광고), 사전, 지식iN, 카테고리, 비즈사이트(광고), 사이트, 지역정보, 블로그, 책, 카페, 동영상, 전문자료, 음악, 최신뉴스, 웹 페이지, 이미지순으로결과가나타난다. 같은 방식으로 야후 코리아에서 검색을 하면 관련 검색어, 야후!여행 바로가기, 스폰서링크 (광고), 비즈링크 (광고), 플러스링크(광고), 프리미엄사이트 (광고), 지식, 블로그+게시판, 이미지, 사전, 카테고리, 웹, 뉴스, 거기, 뮤직, 동영상순으로표시된다. 하지만 이 순서가 절대적인 것은 아니다. 검색어에 따라 어떤 항목은 제외되기도 하고 표시되는 순서가 달라지기도 한다. 중요한 건요즘 대부분의 검색 엔진들이 이용자들에게 정말 중요한 정보를제일 먼저 보여주지는 않는다는 것이다. 회사의 이익과 정책에 부합되는 배치가 우선이다. 검색할 때마다 제일 위에 떠오르는 수많은광고링크들이그걸반영하고있다.
|

 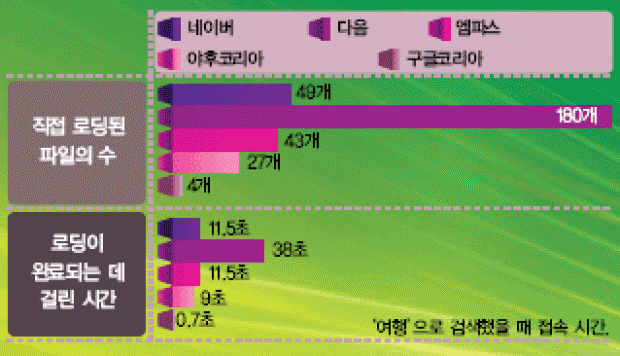   | 검색 엔진 진검승부 검색 엔진 속도를 외부에서 객관적으로 평가하기는 어렵다. 서버의 작동 시간 외에도 회선의 상태, 검색어의 종류에 따라 결과가조금씩 달라지기 때문이다. 그러므로 여기서 몇 가지 방법으로 잰검색속도는절대적인기준은아니다. 검색속도 웹사이트 접속 시간을 알려주는‘OctaGate Site Timer’(http://www.octagate.com/service/SiteTimer/?Target=AJAX)를이용해서 결과를 쟀다. 다음은각 검색 사이트 시작 페이지의접속시간이다. 구글을 제외한 모든 사이트가 포털의 일부이기 때문에 메인 페이지의 접속에서는 구글과 다른 사이트가 엄청난 차이를 보였다. 하지만 모든 파일이 로딩되지 않아도 검색을 시작할 수 있다는 점,시작 페이지의 컨텐츠가 유동적으로 구성된다는 점, 회선의 상태등은 감안해야 할 것이다. 그럼에도 구글의 시작 페이지에 접속되는저짧은시간은독보적인장점이라할수있겠다. 이번에는 검색어‘여행’을 집어넣어서 나온 결과 페이지의 접속 시간이다. 여기서도 비슷한 결과가 나타났다. 구글은 놀라운 속도를보여줬지만 상대적으로 로딩된 파일의 수가 적음을 알 수 있다. 다른사이트들은부가정보들을함께보여주느라속도가느려졌다. 검색된 페이지의 용량 검색 페이지별 용량을 비교해보았다. 우선 시작 페이지부터 살펴보면다음과같다. 웹 페이지 구성 파일 중 비교적 큰 비중을 차지하는 이미지 파일의수와전체로딩되는페이지의용량은위와같았다. 구글을 제외한 다른 검색 엔진들의 결과 페이지 총 용량이 큰 이유는 대부분 광고에 쓰이는 이미지와 이미지/동영상 검색결과를 보여주기 위한 이미지들이 거기에 포함되어 있기 때문이다. 참고로구글 코리아의 이미지 검색을 이용해‘여행’을 검색했더니 이미지파일의개수는24개, 총용량은117KB의결과가나왔다. 검색 결과에 대한 만족도에 절대적인 기준을 잡기는 어렵다. 어떤검색 엔진이 더 좋은 결과를 보여주는지, 더 만족할 만한 자료들을찾아내는지에 대한 판단은 쓰는 사람의 검색 패턴이 어떤지에 따라달라질수있기때문이다. 필자의 검색 패턴을 적어보자면 실생활과 관련된 정보들은 네이버나 다음, 엠파스의 지식관련 서비스(네이버의 지식iN, 다음의 신지식, 엠파스의 열린 지식)를 주로 이용한다. 예를 들어‘홍대에서 분당 가는 버스’라든지‘신나는 댄스곡’‘작은 mp3 플레이어 추천’같은 식으로 우리나라 사정에 맞는 것들을 검색하면 유용한 정보를 얻을 수 있다. 하지만 잘못된 정보도 종종 있기 때문에 중요한내용일수록 몇번씩 검색을 다시 해보는 것이 좋다. 책이나 음반,음식점 등을 찾을 때도 각각의 쇼핑몰 등에서 검색할 수 있지만 포털의 검색 사이트나 가격비교 사이트에서 검색하면 여기저기 옮겨다니는수고를덜수있다. |
| 반면 객관적인 정보나 컴퓨터 프로그래밍 등과 관련된 정보는 구글에서 얻는 편이다. 구글은 정보를 찾는 속도가 빠를 뿐만 아니라여러 나라 웹 페이지들도 함께 보여주기 때문에 외국어를 조금 할줄 안다면 금상첨화로 쓸 수 있다. 잘못된 정보가 있을 확률도 지식 관련 서비스들에 비해 적은 편이다. 예를 들어‘html cssduplicate character bug’라고 적으면 HTML 문서를 작성할 때발생하는 duplicate character 버그에 관한 정보를 정확하게 찾을수있다. |
| 웹2.0 시대의 검색 검색 엔진은 한 가지 형태로 존재하지 않는다. 그리고 많은 사람들이 이용하는 큰 검색 사이트들은 대부분 포털을 겸하고 있다. 최근의 정보 수집 경향은 단순히 로봇이 긁어온 자료를 보여주는데 그치지 않고 사람들이 직접 정보를 입력하거나 재분류하는 형태로변하고 있다. 그동안 네이버나 다음 등 국내 포털들이 검색 로봇으로 자료들을 모아 한꺼번에 보여주는 식으로 이용자들을 끌었던반면, 최근에는 특이한 형태의 검색 서비스들이 인기를 모으고 있다. 올블로그(http://www.allblog.net)나 태터툴즈의 이올린(http://www.eolin.com) 같은 각종 메타 블로그 서비스들은 이미검색 사이트로서 충분한 역할을 해내고 있다. 메타 블로그 서비스들의 장점은 이용자들이 자발적으로 글을 전송하고 출처도 비교적명확해신뢰할만한 정보를많이만날수있다는것이다. 갈수록 스팸성 웹 페이지들이 급격히 늘어나고 있어 검색 로봇이수집한 자료라고 해도 이용자들이 다시 그것을 확인하고 분류해야정확한 정보를 얻을 수 있다. 구글은 페이지랭크(PageRank) 등으로 검색 결과를 처리해 보여주고 있지만 최근 들어 이용자들이 검색결과를손보는일이늘고있다. 검색 사이트의 큰 축을 차지하고 있는 가격비교 사이트 역시 쇼핑하기 전에 한번쯤 들러서 가격을 확인하는 필수 코스로 자리 잡고있다. 얼마 전에는 각종 리뷰를 검색할 수 있는‘레뷰’(RevU,http://www.revu.co.kr) 서비스도 생겼다. 한국교육학술정보원에서 서비스하는‘RISS’(http://www.riss4u.net)는 학술자료가 필요한 사람들에게는 꽤 유용하다. 모든 사람들에게 개방되어있는‘위키피디아’(http://www.wikipedia.org, 한글 사이트는http://ko.wikipedia.org이다)는 인터넷 시대의 백과사전으로 불린다. 이용자들이 자기가 알고 있는 정보를 직접 입력하고 부족하거나 잘못된 정보를 적극적으로 수정/추가/보완할 수 있기 때문에위키피디아의 활용도는무궁무진하다고 할수있다. 인터넷이라는 공간이 커지면 커질수록 검색 엔진의 필요성은 점점더 높아진다. 하지만“구술이 서 말이어도 꿰어야 보배”라는 속담처럼 너무 많은 정보는 오히려 사람들로 하여금 무엇을 찾아야하는지 헷갈리게 한다. 지금의 검색은 단순히 모든 자료를 보여주기만 하는 것이 아닌, 분야를 특화시키거나 편리한 기능을 탑재하는것은 물론 적극적인 개인화를 꾀하는 방향으로 나아가고 있다. 특정 이용자에게 꼭 필요한 정보, 그들이 궁금해 할 것 같은 내용을미리보여주는검색엔진이각광을받는다. |



| 사람들은 단순히 수천만 명 중 하나인 익명의 네티즌으로 네이버나 구글에서 검색을 한다고 생각하지만, 검색 사이트들은 그들이시도할 수 있는 모든 방법을 동원해 누가 무엇을 어떻게 검색하는지에 대한 자료까지 모은다. 우리의 검색 패턴뿐만 아니라 인터넷이용, 소비, 더 나아가 생활 패턴까지 검색 엔진에 모두 쌓이고 있다는것이다. 물론그것들은우리를편하게만들어주기도 한다. 하지만 이런 게 정말 좋기만 한 걸까? 지식이란 스스로 노력하고시간을 들여 얻어야 오래 가는 법이다. 우리는 막강한 검색 엔진덕분에 너무나 쉽게 정보를 얻는다. 가끔‘머잖아 우리는 인터넷없이는 아무 것도 알지 못하는 바보가 되는 것이 아닐까’하는 생각이 들기도 한다. 조금 불편하더라도 들여다보고 찾아보면서 조금씩 조금씩 올바른 정보를 얻게 해주는 진정한‘검색 영웅’이 나왔으면좋겠다. |
